EC2 Storms
02/12/2010
Below is a graph of latency for requests coming into three load balancers (the dashed line is the latency for requests to the domain that fronts the three LBs, which does DNS round-robin to the three load balancers). As you can see, requests to two of the three load balancers are extremely slow (the orange and blue lines), while requests to the third load balancer (the green line) are consistently fast.
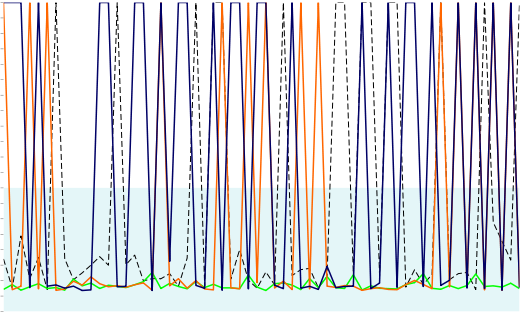
All three load balancers front the same set of back-end machines. The only difference is that the green load balancer is in the same 'availability zone' as the back-ends, while the blue and orange load balancers are in different availability zones. Normally this isn't a problem, but earlier this week we began to see this type of deterioration. At the time, though, we only tracked latency to the domain, not individually for the three load balancers. The degradation also happened to correspond with a spike in traffic, so initially I assumed the problem was with my back-end code.
Lots of investigation ruled out the back-ends, though, at which point we started looking elsewhere, eventually coming to the conclusion that it had to do with cross-availability-zone traffic. Lots of time down the drain, all because something changed in EC2 land.
This is one of the drawbacks of deploying at large scale on EC2 - the network is a complete black box. Over the last six months I've spent lots of time fighting fires. I've come to call events like these "EC2 Storms" because out of the blue, with absolutely no changes to the software or configuration, everything will suddenly tank. A few hours or days later things clear up again and everything looks fine.